I have been trying to locate the cause of a seemingly random bug in KernOS, and after a long investigation, I finally pinned it down.
On hindsight, the bug could have been reasoned out much earlier as the investigation led to more and more credible clues along the way. It’d be a fun detective challenge for you to follow along and see if you can reason out the issue without using as many clues.
To do this, I will lay out my investigation process and label the important clues I discovered chronologically.
Table of contents/clues
- Bug behavior 1
- Bug behavior 2
- Stepping through gdb, instrumenting gdb
- Ruling out page directory setup, page fault handler, kernel heap allocation
- Instrumenting qemu
- Ruling out timer interrupt handler
- Noticing pattern of interrupt that causes bug
- Fixing the bug
The first time the bug was observed was when I was implementing a page fault mechanism. Where a memory access on an unmapped virtual memory address will cause a page fault exception. Which in turn leads to allocating a physical page frame, and updating the page directory entry.

For context, the 0 – 8MB physical memory range is identity mapped to virtual memory, in addition, the first 4KiB page remains unmapped to catch nullptr dereferencing. In other words, any other memory address reference will cause an exception. And below is the code to test whether virtual memory works.
void MemoryTest()
{
kprintf("Test %i: Page fault and virtual memory mapping\n", ++TestCount);
volatile uint32_t *Mem = (uint32_t*) 0x500000; // 0 - 8MB is already mapped
*Mem; // won't cause Page fault exception
volatile uint32_t *Mem2 = (uint32_t*) 0x900000;
*Mem2 = 1; // memory access causes Page Fault
}
Clue 1: The bug was that about 1 in 5 runs, right after 0x900000 is mapped, I would get another page fault exception at either address 0x3
In addition to virtual memory mapping, I also have a custom vector container test. Since this vector container isn’t from STL, heap allocation of the elements is done (in a ghetto manner) by reserving a chunk of memory in the kernel’s .text section, which is managed by a linked list (K&R style). The vector test looks like below
void VectorTest()
{
kprintf("Test %i: Vector and kmalloc/free\n", ++TestCount);
KL::Vector V(5);
V[2] = 5;
V[4] = 15;
V.Pushback(30);
V.Pushback(31);
kassert(V[2] == 5, "Vector[] failed\n");
kassert(V[6] == 31, "Vector::Pushback failed\n");
kassert(V.Back() == V[6], "Vector::Back failed\n");
}
Any of the asserts above would fail randomly, and once again, with the frequency of once in a few kernel boots.
To further figure out what’s going on, I added a series of vector indexing as below.
void VectorTest()
{
kprintf("Test %i: Vector and kmalloc/free\n", ++TestCount);
KL::Vector V(5);
V[2] = 5;
kputchar("%i", V[2]);
kputchar("%i", V[2]);
kputchar("%i", V[2]);
kputchar("%i", V[2]);
...
kputchar("%i", V[2]);
}
And the output looks like

Clue 2: Where once in a while, the indexing would return 0, and in those cases, it would also trigger a page fault at address 0x0.
Stepping through gdb, instrumenting gdb
Given the two above random behaviors, the first thing that came to mind was to use gdb to figure out how things like V[2] could suddenly return a different value. After much trial, I could never reproduce any of the buggy behavior while single stepping.
Perhaps I just wasn’t running the kernel enough times to catch the bug occurring. Single stepping was also pretty tedious, so next I tried to run the kernel many times, and simply log every executed instructions (using gdb on qemu on the kernel), hoping to analyze the executed code later when the bug occurs.
Here’s how I was running qemu and gdb,
qemu-system-i386 -s -S kern.bin
# -s means to allow gdb to connect at port tcp::1234
# -S means to stop at first instruction
And in gdb
target remote connection :1234
set pagination off
set logging on
display/i $pc
while 1
si
end
Clue 3: No matter how many times I run the kernel and log the instructions, the bug NEVER occurs.
Ruling out page directory setup, page fault handler, kernel heap allocation
Stumped by the fact that gdb isn’t able to record the behavior, I decided to move on from approaching the issue through debugging for the time being. I nonetheless felt that it’s related to virtual memory/page fault handling that was the culprit.
Thus I carefully inspected all code related to page fault handling.
Clue 4: It is not related to
- Page fault exception handler
- Page frame allocation
- Kernel heap memory allocator
- Page directory, or page table entry update
At this point, I decided that I needed to look into qemu in order to understand what’s going on. Compiling qemu and learning about how it works. I started poking around the source code and realized that logging qemu instructions executing the kernel does allow the buggy behavior to occur. That’s a very important progress, since as long as I can reproduce/log the sequence of instructions that caused the bug, I can eventually figure this out. Qemu source code is still one complex beast though. But at least the bug is no longer elusive.
Before this, the bug almost felt supernatural, as if it knows not to manifest when you’re looking at it.
After some fumbling, I decided to start from inspecting qemu’s handling of page fault exceptions. The function where exceptions and interrupt are handled in qemu is do_interrupt_all. And logging it, I realized that if the bug occurs, it would occur on the 314-th call to do_interrupt_all. This is pretty unscientific, but I decided to log qemu instructions on the 313-th call and 314-th call and diff-ing them to see where they diverges.
Here’s what I got
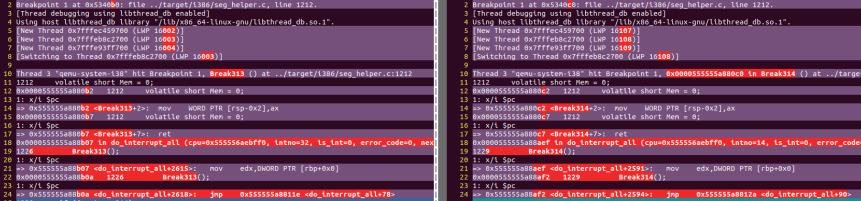
You can ignore Break313, Break314, it’s simply a dummy function I inserted into qemu’s do_interrupt_all function to allow easy breaking. By chance, I noticed an important difference between the 313-th and 314-th call. Looking at line 18 in the image above, you can see that the intno on the left is 32, while the one on the right is 14.
So it looks like interrupt no 32 occurs before interrupt no 14. I recall that a page fault exception is 14, and since the bug had always been related to page fault exception, that wasn’t surprising at all. But what is interrupt no 32? And does the fact that it occurred right before the page fault exception be the cause for our bug?
Looking up the source code of my kernel, I had remapped interrupts on my Programmable Interrupt Controller according to standard ISA IRQ numbers, with an offset of 0x20. Thus interrupt number 32 corresponds to a timer interrupt.
This is a revelation. I had never suspected that the bug is related to a timer interrupt, but a timer interrupt bug seems to fit the behavior of the bug’s randomness.
Now why would a timer interrupt not manifest in gdb? Armed with this information, it didn’t take long to confirm that qemu on gdb by default disables the clock timer, and IRQ interrupts. The qemu docs here indicates how to enable them both in gdb debugging. And sure enough, once I enabled both, the bug now shows up in gdb as well.
Clue 5: The bug occurs after a timer interrupt.
Ruling out timer interrupt handler
On hindsight, the problem is obvious now, but it still didn’t cross my mind how the timer interrupt could be causing the buggy behaviors we had observed such as 1) immediate page fault right after a page fault handler, and 2) indexing vector giving different value.
Thus I continued by inspecting timer interrupt related code. Below is the InterruptTimerHandler
extern "C" void InterruptTimerHandler()
{
{
IRQAcknowledge AckEOI(INTRP::IVT::TIMER);
}
if (++timer_ticks >= TICKS_PER_SECOND)
{
++seconds_since_boot;
timer_ticks = 0;
}
if (seconds_since_boot == 3)
{
seconds_since_boot = 0;
PROCESS::Reschedule();
}
}
It’s very simple, basically it acknowledges the IRQ, and increments a count. And if the count reaches 3 seconds, call the process scheduler. I don’t see any issue with the timer handler
Clue 6: Interrupt timer handler is correct.
Noticing pattern of interrupt that causes bug
Now I started to suspect that it was qemu’s i386 hardware emulation that was buggy. That it somehow messes up the system’s environment after a timer interrupt. I felt this was unlikely, but I thought of Sherlock Holmes’ quote and went on anyway.
“When you have eliminated the impossible, whatever remains, however improbable, must be the truth”
Stepping through qemu’s source, I noticed the code snippet below,
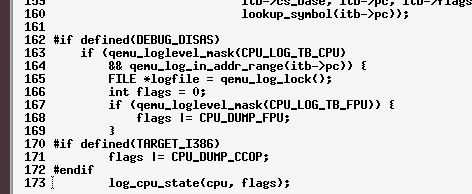
Looks like qemu has a log mode that prints out assembly instructions. Duh, I should have rtfm. Turns out qemu has some really sweet debugging print outs.

With interrupt logs, and guest assembly logs (-d int,in_asm) on, here’s the output I obtained (modified for clarity)

In line 9, the CPU is attempting to dereference memory location 0x900000, which as mentioned earlier isn’t yet mapped to physical memory. Thus it immediately triggers a page fault exception, which can be seen in line 11 – 21. Line 18 – 21 is all the page fault handler code that I have omitted since they aren’t the culprit.
We see in line 15 that when the page fault exception occurred, we have EIP at 0x001059a3, which means after the page fault handler, the CPU would execute line 9 again. This is expected behavior as the CPU attempts to continue accessing the memory location 0x900000 after the page has been mapped.
However, before the CPU can execute instruction in line 9 again, a timer interrupt occurs, as can be seen in line 23. Notice also that EAX in line 13, and 25 are both 0x900000, since that’s the address we are attempting to assess when the page fault exception, and timer interrupt occurred respectively.
After the timer interrupt, the CPU now again tries to resume where it left off in EIP 0x001059a3. However, we notice a 2nd page fault exception now happens immediately in line 33. What stood out now is that EAX is now 0x3. This means that the CPU is trying to assess memory location 0x3. And since the first 4KiB is intentionally unmapped (explained earlier to catch nullptr errors), a page fault exception is triggered.
Clue 7: EAX after timer interrupt has been changed
We are finally at the last section! If you are still with me, the bug is that our timer interrupt handler doesn’t restore registers after it is called. Thus whenever a timer interrupt occurs, it leaves common registers in a changed state, in particular, EAX is set to 0x3. And the behavior according to
System V ABI calling convention is that the registers EAX, EDX, and ECX are free to be used and need not be preserved.
The problem is that timer interrupt can be called anywhere interrupt is enabled, which means if it is called right before an instruction that expects to use some value stored in the register EAX, it will be containing junk instead.
This explains the two buggy behaviors. In 1) the unmapped virtual memory access case, EAX which is supposed to contain the now mapped memory location, is now 0x3, leading to a second page fault exception. Whereas in 2) the vector indexing access case, the indexed element is already contained in EAX, but it is corrupted by the timer interrupt before it is being used.
Finally, the fix is to store and restore all the unpreserved registers before we execute the timer interrupt handler.
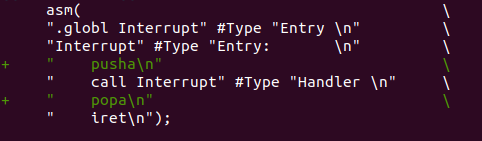
In all, the most useful thing I learned is to utilize qemu’s instruction and interrupt dump, especially in a kernel building project. The quality of the information produced is just a gold mine.
