Specifying the Kalman-Filter algorithm
The Bayes filter elaborated in the previous post gave us the basis of evolving a posterior state distribution across time. However, there are several issues we have to sort out before we can implement a Bayes filter for practical usage,
- the exact distributions of initial state
, measurement function
, and transition function
are often unknown, and
- even if they are known, the evaluation of product of distributions (e.g., transition density function *
), and integration of distributions (e.g., transition function over range of prior state) generally requires numerical methods as there are no closed-form solutions. These increases computational requirement and could cause our robot to be inappropriate for real-time usages.
One way to address the issues above is to make some assumptions that allows our Bayes algorithm to be more amenable. Let’s assume that our state evolves according to a linear Gaussian process. This allows us to reformulate our functions as follows,

where,

A Bayes-filter that follows Gaussian process is also known as a Kalman-filter. Our interest today is to show that in a Kalman-filter, the conditional state posterior distribution is also a Gaussion process. In other words, that the following holds,

Restating the Bayes algorithm under a Kalman-filter gives us,

Derivation of Kalman-filter algorithm
We shall now prove that the Kalman-filter algorithm results in the state posterior distribution (2) by induction. For this, we need to show that,

implies,

The first point is true because our initial state distribution is assumed to be normal within the context of Kalman-filter. The second point will be shown as part of our derivation of the Kalman-filter algorithm.
Our goal is to express 



We first show that the integrand above evaluates to a normal distribution. From (1), we know that

 as,
as,

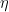
We want to rearrange the terms in the exponential in (4) in such a way that allows us to integrate over 

- decompose
into two functions, one with the terms
respectively, and
- identify a form for
such that the integral over
To do the above, we observe that the function
- quadratic in
, and
- exponential over the quadratic
This suggests that if we can collect the terms with
We can construct a normal distribution from an exponential quadratic (see Appendix). By applying first and second order differentiation to 

Setting the first derivative to 0 and solving for
![\displaystyle x_{t-1} = \Psi_t[{A_t}^T {R_t}^{-1}(x_t-B_t u_t) + {\Sigma_{t-1}}^{-1} \mu_{t-1}] \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++x_%7Bt-1%7D+%3D+%5CPsi_t%5B%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D+%5Cmu_%7Bt-1%7D%5D+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
Thus using the 
![\displaystyle \begin{array}{rcl} L_t(x_{t-1},x_t) & = & \frac{1}{2} {(x_{t-1} - \Psi_t[{A_t}^T {R_t}^{-1}(x_t-B_t u_t) + {\Sigma_{t-1}}^{-1} \mu_{t-1}])}^T {\Psi_t}^{-1} \\ && \negmedspace (x_{t-1} - \Psi_t[{A_t}^T {R_t}^{-1}(x_t-B_t u_t) + {\Sigma_{t-1}}^{-1} \mu_{t-1}]) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++L_t%28x_%7Bt-1%7D%2Cx_t%29+%26+%3D+%26+%5Cfrac%7B1%7D%7B2%7D+%7B%28x_%7Bt-1%7D+-+%5CPsi_t%5B%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D+%5Cmu_%7Bt-1%7D%5D%29%7D%5ET+%7B%5CPsi_t%7D%5E%7B-1%7D+%5C%5C+%26%26+%5Cnegmedspace+%28x_%7Bt-1%7D+-+%5CPsi_t%5B%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D+%5Cmu_%7Bt-1%7D%5D%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
With this, let us find 
![\displaystyle \begin{array}{rcl} L_t(x_t) & = & L_t - L_t(x_{t-1}, x_t) \\ & = & \frac{1}{2} {(x_t - A_t x_{t-1} - B_t u_t)}^T {R_t}^{-1} (x_t - A_t x_{t-1} - B_t u_t)\\ && \negmedspace + \ \frac{1}{2}{(x_{t-1}-\mu_{t-1})}^T{\Sigma_{t-1}}^{-1}(x_{t-1}-\mu_{t-1})\\ && \negmedspace - \ \frac{1}{2} { ( x_{t-1} - \Psi_t[{A_t}^T {R_t}^{-1}(x_t-B_t u_t) + {\Sigma_{t-1}}^{-1} \mu_{t-1}] ) }^T {\Psi_t}^{-1} \\ && \negmedspace ( x_{t-1} - \Psi_t[{A_t}^T {R_t}^{-1}(x_t-B_t u_t) + {\Sigma_{t-1}}^{-1} \mu_{t-1}] ) \end{array}\ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D++L_t%28x_t%29+%26+%3D+%26+L_t+-+L_t%28x_%7Bt-1%7D%2C+x_t%29+%5C%5C+%26+%3D+%26+%5Cfrac%7B1%7D%7B2%7D+%7B%28x_t+-+A_t+x_%7Bt-1%7D+-+B_t+u_t%29%7D%5ET+%7BR_t%7D%5E%7B-1%7D+%28x_t+-+A_t+x_%7Bt-1%7D+-+B_t+u_t%29%5C%5C+%26%26+%5Cnegmedspace+%2B+%5C+%5Cfrac%7B1%7D%7B2%7D%7B%28x_%7Bt-1%7D-%5Cmu_%7Bt-1%7D%29%7D%5ET%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%28x_%7Bt-1%7D-%5Cmu_%7Bt-1%7D%29%5C%5C+%26%26+%5Cnegmedspace+-+%5C+%5Cfrac%7B1%7D%7B2%7D+%7B+%28+x_%7Bt-1%7D+-+%5CPsi_t%5B%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D+%5Cmu_%7Bt-1%7D%5D+%29+%7D%5ET+%7B%5CPsi_t%7D%5E%7B-1%7D+%5C%5C+%26%26+%5Cnegmedspace+%28+x_%7Bt-1%7D+-+%5CPsi_t%5B%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D+%5Cmu_%7Bt-1%7D%5D+%29++%5Cend%7Barray%7D%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
Substituting
![\displaystyle \begin{array}{rcl} L_t(x_t) & = & \frac{1}{2}{(x_t - B_t u_t)}^T {R_t}^{-1}(x_t - B_t u_t) \\ && \negmedspace +\ \frac{1}{2}{\mu_{t-1}}^T {\Sigma_{t-1}}^{-1}\mu_{t-1} \\ && \negmedspace -\ \frac{1}{2}{ [{A_t}^T{R_t}^{-1}(x_t-B_t u_t) +{\Sigma_{t-1}}^{-1}\mu_{t-1} ]}^T {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1}) }^{-1} \\ && \negmedspace [{A_t}^T{R_t}^{-1}(x_t-B_t u_t) +{\Sigma_{t-1}}^{-1}\mu_{t-1}] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++L_t%28x_t%29+%26+%3D+%26+%5Cfrac%7B1%7D%7B2%7D%7B%28x_t+-+B_t+u_t%29%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t+-+B_t+u_t%29+%5C%5C+%26%26+%5Cnegmedspace+%2B%5C+%5Cfrac%7B1%7D%7B2%7D%7B%5Cmu_%7Bt-1%7D%7D%5ET+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%26+%5Cnegmedspace+-%5C+%5Cfrac%7B1%7D%7B2%7D%7B+%5B%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5D%7D%5ET+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29+%7D%5E%7B-1%7D+%5C%5C+%26%26+%5Cnegmedspace+%5B%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D%5D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
The forms of 
-
, and
-
With the decomposition of

We notice from (7) that 
![\displaystyle \begin{array}{rcl} \frac{\delta L_t(x_t)}{\delta {x_t}} & = & {R_t}^{-1}(x_t-B_t u_t) - {R_t}^{-1} A_t {({A_t}^T {R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1} \\ && \negmedspace [{A_t}^T {R_t}^{-1}(x_t-B_t u_t)+{\Sigma_{t-1}}^{-1}\mu_{t-1}] \\ \frac{\delta^2 L_t(x_t)}{\delta {x_t}^2} & = & {R_t}^{-1} - {R_t}^{-1}A_t{({A_t}^T{R_t}^{-1}A_t+{\Sigma_{t-1}}^{-1})}^{-1}{A_t}^T{R_t}^{-1} \end{array}\ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D++%5Cfrac%7B%5Cdelta+L_t%28x_t%29%7D%7B%5Cdelta+%7Bx_t%7D%7D+%26+%3D+%26+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+-+%7BR_t%7D%5E%7B-1%7D+A_t+%7B%28%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D+%5C%5C+%26%26+%5Cnegmedspace+%5B%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29%2B%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D%5D+%5C%5C+%5Cfrac%7B%5Cdelta%5E2+L_t%28x_t%29%7D%7B%5Cdelta+%7Bx_t%7D%5E2%7D+%26+%3D+%26+%7BR_t%7D%5E%7B-1%7D+-+%7BR_t%7D%5E%7B-1%7DA_t%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t%2B%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7D++%5Cend%7Barray%7D%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=000000&s=0&c=20201002)
Using inversion lemma (see Appendix), we can rewrite (9) as,

The intuitive interpretation of (10) is that the variance of our normal distribution, 
- the error in transition process (1),
, and
- the variance of the prior period’s belief,
evolved through the linear process

Next, we solve for 
![\displaystyle \begin{array}{rcl} 0 &=& {R_t}^{-1}(x_t-B_t u_t) \\ &-& {R_t}^{-1} A_t {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1}[{A_t}^T {R_t}^{-1}(x_t-B_t u_t) + {\Sigma_{t-1}}^{-1}\mu_{t-1}] \\ &\iff& {R_t}^{-1}(x_t-B_t u_t) \\ &=& {R_t}^{-1} A_t {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1}[{A_t}^T {R_t}^{-1}(x_t-B_t u_t) + {\Sigma_{t-1}}^{-1}\mu_{t-1}] \\ &\iff& [{R_t}^{-1} - {R_t}^{-1} A_t {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1}{A_t}^T {R_t}^{-1}](x_t-B_t u_t) \\ &=& {R_t}^{-1} A_t {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1}{\Sigma_{t-1}}^{-1}\mu_{t-1} \\ &\iff& {(R_t+A_t\Sigma_{t-1}{A_t}^T)}^{-1}(x_t-B_t u_t) \\ &=& {R_t}^{-1} A_t {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1}{\Sigma_{t-1}}^{-1}\mu_{t-1} \text{ by inversion lemma} \\ &\iff& (x_t-B_t u_t) \\ &=& (R_t+A_t\Sigma_{t-1}{A_t}^T){R_t}^{-1} A_t {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1}{\Sigma_{t-1}}^{-1}\mu_{t-1} \\ &\iff& x_t = B_t u_t + (R_t+A_t\Sigma_{t-1}{A_t}^T){R_t}^{-1} A_t {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1}{\Sigma_{t-1}}^{-1}\mu_{t-1} \\ &\iff& x_t = B_t u_t + (I+A_t\Sigma_{t-1}{A_t}^T{R_t}^{-1}) A_t {({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}^{-1}{\Sigma_{t-1}}^{-1}\mu_{t-1} \\ &\iff& x_t = B_t u_t + (I+A_t\Sigma_{t-1}{A_t}^T{R_t}^{-1}) A_t [{\Sigma_{t-1}}{({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}]^{-1}\mu_{t-1} \\ &\iff& x_t = B_t u_t + (A_t+A_t\Sigma_{t-1}{A_t}^T{R_t}^{-1}A_t) [{\Sigma_{t-1}}{({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}]^{-1}\mu_{t-1} \\ &\iff& x_t = B_t u_t + A_t(I+\Sigma_{t-1}{A_t}^T{R_t}^{-1}A_t) [{\Sigma_{t-1}}{({A_t}^T{R_t}^{-1}A_t + {\Sigma_{t-1}}^{-1})}]^{-1}\mu_{t-1} \\ &\iff& x_t = B_t u_t + A_t(I+\Sigma_{t-1}{A_t}^T{R_t}^{-1}A_t) {(I+{\Sigma_{t-1}}{A_t}^T{R_t}^{-1}A_t)}^{-1}\mu_{t-1} \\ &\iff& x_t = B_t u_t + A_t\mu_{t-1} \\ &\iff& x_t = A_t\mu_{t-1} + B_t u_t \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++0+%26%3D%26+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%5C%5C+%26-%26+%7BR_t%7D%5E%7B-1%7D+A_t+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%5B%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D%5D+%5C%5C+%26%5Ciff%26+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%5C%5C+%26%3D%26+%7BR_t%7D%5E%7B-1%7D+A_t+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%5B%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D%5D+%5C%5C+%26%5Ciff%26+%5B%7BR_t%7D%5E%7B-1%7D+-+%7BR_t%7D%5E%7B-1%7D+A_t+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%7BA_t%7D%5ET+%7BR_t%7D%5E%7B-1%7D%5D%28x_t-B_t+u_t%29+%5C%5C+%26%3D%26+%7BR_t%7D%5E%7B-1%7D+A_t+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+%7B%28R_t%2BA_t%5CSigma_%7Bt-1%7D%7BA_t%7D%5ET%29%7D%5E%7B-1%7D%28x_t-B_t+u_t%29+%5C%5C+%26%3D%26+%7BR_t%7D%5E%7B-1%7D+A_t+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5Ctext%7B+by+inversion+lemma%7D+%5C%5C+%26%5Ciff%26+%28x_t-B_t+u_t%29+%5C%5C+%26%3D%26+%28R_t%2BA_t%5CSigma_%7Bt-1%7D%7BA_t%7D%5ET%29%7BR_t%7D%5E%7B-1%7D+A_t+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+x_t+%3D+B_t+u_t+%2B+%28R_t%2BA_t%5CSigma_%7Bt-1%7D%7BA_t%7D%5ET%29%7BR_t%7D%5E%7B-1%7D+A_t+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+x_t+%3D+B_t+u_t+%2B+%28I%2BA_t%5CSigma_%7Bt-1%7D%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7D%29+A_t+%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5E%7B-1%7D%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+x_t+%3D+B_t+u_t+%2B+%28I%2BA_t%5CSigma_%7Bt-1%7D%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7D%29+A_t+%5B%7B%5CSigma_%7Bt-1%7D%7D%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+x_t+%3D+B_t+u_t+%2B+%28A_t%2BA_t%5CSigma_%7Bt-1%7D%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t%29+%5B%7B%5CSigma_%7Bt-1%7D%7D%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+x_t+%3D+B_t+u_t+%2B+A_t%28I%2B%5CSigma_%7Bt-1%7D%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t%29+%5B%7B%5CSigma_%7Bt-1%7D%7D%7B%28%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t+%2B+%7B%5CSigma_%7Bt-1%7D%7D%5E%7B-1%7D%29%7D%5D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+x_t+%3D+B_t+u_t+%2B+A_t%28I%2B%5CSigma_%7Bt-1%7D%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t%29+%7B%28I%2B%7B%5CSigma_%7Bt-1%7D%7D%7BA_t%7D%5ET%7BR_t%7D%5E%7B-1%7DA_t%29%7D%5E%7B-1%7D%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+x_t+%3D+B_t+u_t+%2B+A_t%5Cmu_%7Bt-1%7D+%5C%5C+%26%5Ciff%26+x_t+%3D+A_t%5Cmu_%7Bt-1%7D+%2B+B_t+u_t+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Thus, we obtain the mean of the normal distribution as,

With (11) as the mean, and (10) as the variance parameter of the normal distribution of (8), we can now say that,

Now the last remaining step we have to do is to combine the transition distribution with the measurement distribution,

Since we now know that both 

Let us collect the exponential terms in (14) as 

Again we notice that (14) is exponential quadratic in 

Setting (15) to zero, and substituing

We now have a complete specification of 
Kalman Gain
We could have used (16) and (15) in our Kalman-filter algorithm as below, and call it a day.

However another representation that in more commonly used exists. It also is more efficient by allowing us to avoid having to evaluate double inverses. By introducing a Kalman gain term, we can express (17) as,

To go from the variance formulation from (17) to (18), we write
![\displaystyle \begin{array}{rcl} \Sigma_t \ &=& {(C_t}^T{Q_t}^{-1}C_t + {\bar{\Sigma}_t)}^{-1} \\ &=& \bar{\Sigma}_t - \bar{\Sigma}_t {C_t}^T (Q_t + C_t \bar{\Sigma}_t {C_t}^T)^{-1}C_t \bar{\Sigma}_t \\ &=& (I - \bar{\Sigma}_t {C_t}^T [Q_t + C_t \bar{\Sigma}_t {C_t}^T]^{-1}C_t )\bar{\Sigma}_t \\ &=& (I - K_t C_t )\overline{\Sigma}_t \end{array}\ \ \ \ \ (19)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D++%5CSigma_t+%5C+%26%3D%26+%7B%28C_t%7D%5ET%7BQ_t%7D%5E%7B-1%7DC_t+%2B+%7B%5Cbar%7B%5CSigma%7D_t%29%7D%5E%7B-1%7D+%5C%5C+%26%3D%26+%5Cbar%7B%5CSigma%7D_t+-+%5Cbar%7B%5CSigma%7D_t+%7BC_t%7D%5ET+%28Q_t+%2B+C_t+%5Cbar%7B%5CSigma%7D_t+%7BC_t%7D%5ET%29%5E%7B-1%7DC_t+%5Cbar%7B%5CSigma%7D_t+%5C%5C+%26%3D%26+%28I+-+%5Cbar%7B%5CSigma%7D_t+%7BC_t%7D%5ET+%5BQ_t+%2B+C_t+%5Cbar%7B%5CSigma%7D_t+%7BC_t%7D%5ET%5D%5E%7B-1%7DC_t+%29%5Cbar%7B%5CSigma%7D_t+%5C%5C+%26%3D%26+%28I+-+K_t+C_t+%29%5Coverline%7B%5CSigma%7D_t++%5Cend%7Barray%7D%5C+%5C+%5C+%5C+%5C+%2819%29&bg=ffffff&fg=000000&s=0&c=20201002)
Where we define the Kalman gain 
![\displaystyle K_t = \bar{\Sigma}_t {C_t}^T [Q_t + C_t \bar{\Sigma}_t {C_t}^T]^{-1} \ \ \ \ \ (20)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++K_t+%3D+%5Cbar%7B%5CSigma%7D_t+%7BC_t%7D%5ET+%5BQ_t+%2B+C_t+%5Cbar%7B%5CSigma%7D_t+%7BC_t%7D%5ET%5D%5E%7B-1%7D++%5C+%5C+%5C+%5C+%5C+%2820%29&bg=ffffff&fg=000000&s=0&c=20201002)
Next, we show how we can get the mean formulation from (17) to (18),

Finally, combining (12), (19), (20), and (21), we obtain the Kalman-filter algorithm.
Appendix
Constructing Normal distribution
For a normal probability density function 

Let the expression in the exponential be denoted as 
-
set to 0, and
-

Inversion Lemma
The inversion lemma (or also known as Woodbury matrix identity) states that for invertible matrices 

References
Thrun, Sebastian, et al. Probabilistic Robotics. MIT Press, 2010.

In equation (4) and the terms thereafter, shouldn’t R_t be replaced by the total covariance in the expression above it i.e. (A \Sigma_{t-1} A^T + R_t)? Because If (x_t | x_{t-1}, u_t) is distributed as mentioned in the expression above eq. (4), then the covariance term should correspond to that, right?
LikeLike
Good catch! The equation directly above (4) is inaccurate. “A \Sigma_{t-1} A^T + R_t” is the variance of “x_t”, not “x_t | x_{t-1}, u_t”. The covariance for “x_t | x_{t-1}, u_t” should have been stated as R instead. To see this, evaluate the conditional variance using https://en.wikipedia.org/wiki/Conditional_variance#Definition, the x_{t-1} term will cancel out and you’ll be left with R.
LikeLike
Oh yeah, that makes sense. I didn’t think too much about that conditional expression above eq. (4). I took that as the reference and then started working out the remaining equations. I should have thought about that.
Thank you for your prompt response, and, of course, for this derivation!
LikeLike